Simulations is Done
My Master’s in Analytics is 50% complete! With Simulations done, I’ve gained valuable knowledge in: analyzing simulation inputs, outputs and comparing systems. Plus, I got to use Arena. Arena allows you to create simulations super quick. During this class, I stretched a bit of my Python skills and built a Poker Simulator and got to design poker players. More on that later.
Simulation Concepts
Simulations covers lots of concepts useful for future classes. Just a quick list:
- Calculating expectation both in discrete, continuous and multi-variate forms. Lots of integrals. A close cousin is calculating variances.
- How random number generators work. Check out the Mersenne twister. This is behind Python’s random library.
- How to run simulation libraries such as Arena.
- Probability distributions: Bernoulli, Binomial, Geometric, Uniform etc. How to fit them to your data using MLE. How to check if they are a good fit using goodness of fit tests.
- Comparing simulation systems with different confidence interval techniques: independent replications, batch means etc.
We covered more than the above. The above represents some concepts taught in that class.
Finding a Teammate
I decided to team up with Shahin Shirazi, a fellow student. Shahin and I worked on Data Visual Analytics project. Shahin focused on using Python to build a KNN clustering algorithm on Geospatial data. I love programming and when I find a capable student I try to recruit them for a project. Shahin is great! We decided to team up for our simulation project.
Poker Project
Shahin and I decided to build a poker simulator. We called it Decima after the goddess that measures out the lives of men and women. Our Decima would measure out the performance of poker players instead. Our repository can be found here: Decima.
Decima was developed as a single python file with no parameters: poker.py. This was to simplify the effort for the graders. We utilized Python 3.7 for the project. The project defines a set of simulations to run, see the below picture (poker.py file):

Tables, hands, balance and minimum balance represent global parameters. In the above:
- tables – represents the number of poker tables to run. You can think of this as an independent replication.
- hands – number of hands the dealer plays at a table.
- balance – initial player balance. Think of this as $100,000. A sizeable house down payment or a Ferrari. Real high stakes. If you are Bezos, waiter tip, please tip more :).
- minimum balance – how much a player needs to join a game.
Simulations parameter above defines a user friendly name for the simulation and the type of players involved. You can define as many simulations as you want. Though if you define a lot of them, you might be waiting a while for the simulation to complete. My official warning.
Poker Player Types
We defined a bunch of players. Some of them rather complex, others not so much. Below 2 rudimentary ones;
These players always call or bet independent of anything else. I wouldn’t say this is a “smart” strategy, but it’s great to explain our framework. In the above cases, we have a class that inherits from GenericPlayer and has a bet_strategy method. That method has a ton of parameters none of which are optional. Within the body of the function, you have to call (only once): call_bet, raise_bet or fold_bet to cause the player to: call, raise or fold respectively. That’s it.
You can make this as complicated as you would like by adding more methods or data structures.
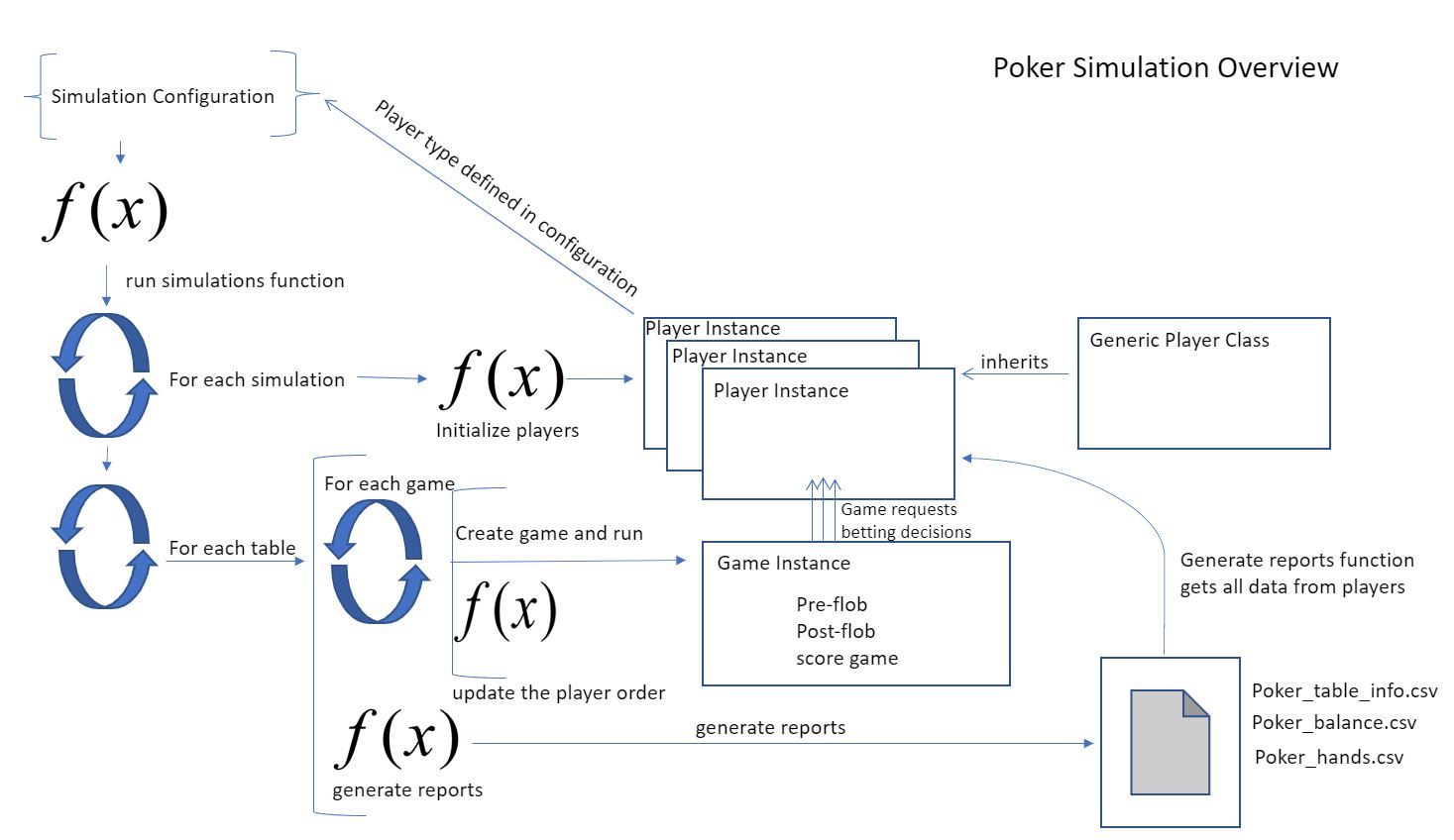
Decima Diagram:
I provide below a diagram of our program. Read from top left to bottom right. The bottom right are 3 CSVs that are produced as outputs for the system. Poker balance is for game balances, poker hands is for decisions made in the poker game and poker table info is just metadata for the simulation itself. All of the CSVs have those convenient foreign and primary keys that all jazzy database folks love and live by. So feel free to join them. Preferably with a good beverage at hand.
Cool Player Types we developed:
Shahin focused on players that were aware of their opponents. His players almost always kicked my player’s butt. Even when they weren’t aware of their opponents they kicked my player’s butt. I guess this whole reinforcement learning thing has some added advantages. That or trying to figure out your opponent when playing poker has some merit. Maybe I’ll get him to update this post with all that poker butt-kicking goodness.
I focused on trying out some really strategies involving data structures I found novel. When I mean novel, I mean: I read 4-5 academic papers, 3 of them mentioned this data structure and so I decided on pure faith that I could build it without considering any time constraints (then somehow pulled it off). Wonderful. What did I build? A Monte Carlo Tree Search algorithm.
A Tree of Monte Carlo Simulations:
So evidently, in the video game and board game communities, they use this concept called a monte carlo tree search algorithm to determine what moves are best to play. I had no idea. It’s also, coincidently, used in AlphaGo. Though coincidently here means one of many algorithms and so I can’t even bother claiming any genius for implementing a half-assed version of it. Still, kind of fun. Here I poach the diagram from Wikipedia for your viewing pleasure: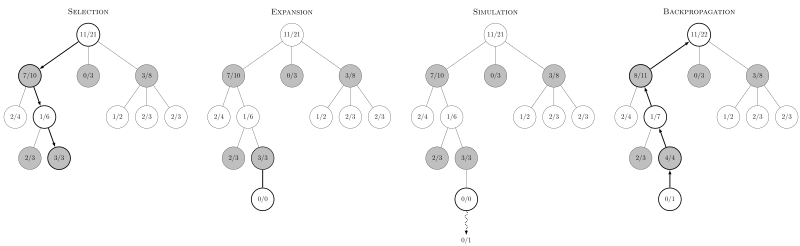
It’s not as complicated as it looks. Each node in the tree represents a players move. Each child is an opponents response to the parent move. So levels of a tree represent different players. Well at least until the player order repeats itself. If you start at the root node and go down, you follow a sequence of moves for a board (video game) up until that point.
How does the algorithm work? Select a node with a missing child. Add said missing child. Use the moves up to that point in time as an initial state for a monte carlo simulation. Play the monte carlo simulation to completion and record the wins and total games played. Propagate the score and total games up the ancestor chain. That’s it! Once you propagate everything up the ancestral chain, your win probabilities update and you can look at all moves to make a decision. One hiccup, how do you choose a node to search if no children are missing. You use the upper confidence bound algorithm. TLDR: a algorithm that balances searching new nodes with exploiting nodes with high win percent.
Next up, Regression and more regression…
Doubling this next summer term with a class on regression and a class that applies regression to different business units. So double regression trouble! Hopefully, I have a cool project to talk about.





